The Scaling Paradigm: What’s Happening to Ethereum?
Decentralizing rollups/ centralized sequencers/ ETH value accrual/ ultra-sound money/ hyperscale L2s & EVM L1s

Special thank you to 0xBreadguy for the review and feedback.

1. Introduction
One of the controversial topics of debate this cycle has been the underperformance of ETH and consequently the speculation of its long-term value proposition. With the rapid growth of Solana over the last year and the frequent push for migrating mainnet users to L2s, Ethereum has taken a backseat as value accrual and mindshare has shifted towards hyper-performant L1s and cost-efficient rollups.
In this report we will unpack a number of topics to get a sense of where the current Infra landscape is (particularly within Ethereum) and the direction it’s heading.
Some of the topics we will cover:
The rollup-centric roadmap
Blobs & Ethereum L1 fee revenue
ETH value accrual
The role of the sequencer
Based rollups & preconfirmations
Hyper-performant L1s and L2s
The core premise will be to analyze the ongoing debate around Ethereum’s rollup-centric roadmap and the value accrual relationship between L2s and ETH L1. We’ll also touch on the spectrum of rollups prioritizing decentralization vs hyperscale. Many Infra protocols are now building on what Ethereum would have envisioned to do in retrospect. Some notable protocols covered in this report that elaborate on this topic are Taiko, MegaETH, and Monad.
2. The Current State of Crypto Infrastructure
During the last 6-12 months the infra landscape within crypto has exploded with new protocols, partially due to the adoption of the modular thesis across all stacks on the infrastructure level. This, coupled with the growing number of L1s has made it clear that we are likely running the same playbook of the last two cycles of infra over consumer applications – a narrative that I believe will continue for some time. The only caveat with this thesis is that it has become a lot more complex. Rollups have become a lot more prominent since late 2022 with the early launches of Arbitrum and Optimism. DA layers and modular scaling solutions have also been added to the mix of infra protocols since the launch of Celestia late last year.
As of October 24, 2024, there are a total of 74 live L2s according to L2beat, with another 81 upcoming projects set to launch under the L2 umbrella of infrastructure-based protocols.

Of these 74 L2s 41 of them can be considered general purpose, with the top 3 (Arbitrum, Base, and Optimism) holding over 70% of the total market share. To put the market distribution into context, the bottom 30 general purpose L2s hold less than a tenth of the market share of Arbitrum alone – a perfect segway into the real discussion at hand, the rollup-centric roadmap and value accrual to ETH mainnet from L2s.
2.1 The Rollup-Centric Roadmap
For the longest time, the rollup-centric roadmap was pushed as the solution to solve all of Ethereum’s scaling problems. As ETH mainnet remained committed to security and decentralization as a settlement layer, the L2s would focus on scaling as the execution layer. In the ideal scenario, a combination of general purpose and app-specific rollups would capture a majority of user activity and accrue enough fees back to mainnet through expanding the liquidity market effects of ETH as an asset. Unfortunately, there are a couple of problems with this bull case for the rollup-centric roadmap that the Ethereum community face today:
An increase in L2 activity does not necessarily equate to a flow of value back to ETH as an asset. (value accrues at different parts of the value chain, i.e. the L2 sequencer level) – L2s accruing the value for themselves while benefiting from the security and decentralization of ETH as a settlement layer
The power law effects of one or a handful of L2s accruing a disproportionate majority of the value, in return leaving Ethereum losing value capture (partially due to blobspace and fee-reduction for rollups post EIP-4844)
2.1 Under the same context – The L2 decides to become its own standalone chain and accrue 100% of the value for itself. (This would only make sense if the L2 gained enough security relative to settling on ETH mainnet, however, there is a case for L2s being forced to use alt-DA that we will touch upon later).
If we consider the first scenario, we can make the case that the modularization of the entire blockchain stack is a proponent for a leakage of value accrual back to ETH. All layers of the stack demand some value accrual: execution, DA, settlement, sequencing, consensus. Whereas in a monolithic structure value accrual was not fragmented pre-rollup-centric roadmap. Albeit, transaction fees and congestion pre-rollups and EIP-4844 where not sustainable in the long-run either – a catch-22 situation in a sense.

To Liam’s point, the market is ultimately determining the bearishness of ETH. It’s price performance is reflective of the narrative of it’s current situation.
It’s also worth noting that the L2 native tokens also demand a level of value accrual as well. The argument could be made that ETH will be the gas token within these ecosystems/ rollups, however, in a market that is highly speculative the most dominant L2 would likely get bid as beta against ETH – this was seen early last year as the OP token was bid up in anticipation of the launch of Base (Base being a part of the OP superchain). Now imagine if Base actually had its own token.
The second scenario posits that L2s are consuming more of the value accrual from the increased user activity and transaction revenue consequent of the minimal overhead of settling and posting calldata back to Ethereum. This scenario is amplified as one or a handful of L2s capture a majority of the user activity. If we had hundreds of rollups all with a relatively proportional amount of user activity and txns posting back to Ethereum, there would be enough demand for blockspace, thus making ETH deflationary once again through saturation of the fee markets.
*A side note to consider is the fragmentation issue with the growing number of rollups. Even in the ideal scenario the problem of fragmentation needs to be abstracted away to a degree for long-term viability.
When a single, or a few dominant L2s disproportionately capture the majority of user activity and txn volume, the cost of settlement to Ethereum does not necessarily increase relative to the value capture of the given L2. This means that the dominant rollup still pays the same to settle on Ethereum as do all the other rollups – and as a result, blockspace demand is reduced (since fewer rollups are settling back to ETH).
This situation of a single dominant L2 capturing a majority of the value is also not a hypothetical case – it is currently what is going on with Base. Monthly activity on base relative to the long-tail of L2s has exploded and it only looks like it’s going to continue.

2.2 Wen ETH burn?
The viewpoint from the Ethereum community on this debate is not around the low fees themselves being the issue, but from a lack of demand, and that once this demand is filled the economic value of ETH would readjust to an equilibrium. ETH burn has reached an all-time-low recently, and this has been a noticeable trend since post-Dencun and the introduction of blobspaces. At the current rate ETH has become net inflationary at roughly ~0.8% a year.

Now there are two options to possibly return to this equilibrium that we will cover:
Increasing user activity on L2s
Increasing the minimum blob fees
Increasing the net active users on the L2s to drive more fees to the L1 and thus reach the rebalancing equilibrium of ETH burn would be the most ideal scenario. However, this is completely path dependent on external factors of the L1. It suggests that we need a level of consumer apps and use cases that would drive user activity to reach the demand threshold of blobspace, or we would need to enter into the bull phase of the cycle similar to that of 2021. The bottom line is that activity needs to increase on the L2s significantly to make this a viable option.
In all likeliness, this could very well be the case in the future. It makes much more sense to have the problem of unfilled demand on the L2s rather than astronomical fees like we saw pre-EIP-4844 (specifically throughout the last bull cycle). Overshooting for higher-throughput and lower fees is not a problem of concern in my opinion, especially with the goal of handing greater user demand down the line.
The counterpoint to this solution is that saturation of blobspace demand is unlikely to yield any significance when it comes to ETH burn. Doug Colkitt highlights an interesting point where the vast majority of marginal transactions are in fact due to low dollar spam and that any increase would lead to a drop-off in price-sensitive activity on L2s.

The second option would suggest that base blob fees are increased, at least in the interim until user activity reaches the demand threshold for ETH to become deflationary again. A potential problem with this path is that there exists a number of alt-DA solutions (Celestia, EigenDA, etc.) that L2s could opt into in the scenario of increased DA costs. The only argument then becomes L2s choosing to settle on Ethereum strictly to inherit its security.
2.3 Batching Transactions – Are L2s actually “ETH Aligned”?
Let’s further dissect the theory that increasing the minimum blob fees would solve the L1 value accrual situation. This assumes that rollups would be fine paying these increased fees. For context, blobspace (a separate fee market for rollups) was introduced post-Dencun that are about 1/10 the price/kb relative to blockspace. Base fees within blobspace are determined based on the amount of the blobspace utilization:
<50% of the blobspace is used = fees remain static/ low
>50% of the blobspace is used = fees begin to increase at around ~12% in the proceeding block
*Each blobspace is limited to 6 blobs
In this scenario we are already seeing L2s take advantage of blobspace utilization in the form of saturating the blobspace up to the 50% capacity to sustain lower fees throughout the concurrent blocks. 0xBreadguy points this out during late March when inscriptions eventually were taking place on blobs, driving the cost of blobspaces up.
L2s were seen to limit their blobs right around the 3 blobs/block to sustain the lower fees, essentially batching these transactions.

A similar scenario occurred during the LayerZero airdrop as $ZRO claims drove up txn counts (specifically for Arbitrum). During this event it would have been cheaper for rollups to simply switch over to posting data directly to the blockspace rather than on blobs. Even more so, L2s using alt-DA like Celestia or EigenDA weren’t subject to the second-order effects of fee spikes on the ETH L1 as were the ones posting data to blobspaces.
0xBreadguy covers this in greater detail in his thread which I highly recommend:

2.4 The Doom Cycle of Bandwidth Limitations
Let’s go back to the first approach of increasing demand on the L2 end, as this indirectly ties back to our dilemma of deliberately increasing blob fees. The whole idea is that L2s, from a business perspective are not incentivized to overpay on fees regardless of being “ETH aligned”, whether this is from an increase in base blob fees or from an indirect increase through higher demand on the L2 end. This also needs to be considered from the user perspective as well, as a majority of users simply don’t care if a chain is “ETH aligned” or not – simple incentives outweigh ideological reasons for the majority of users.
Now let’s assume that a given L2 is in fact ETH-aligned and wants to settle on Ethereum but also needs to scale proportionately as demand on this L2 increases. Yes, value will accrue back to ETH as a result but if the blob limit does not increase to support the higher demand from the L2, it would be forced to opt to an alt-DA solution that could handle its bandwidth requirements. This then becomes yet again a scaling and throughput issue rather than an “alignment” issue. For context the theoretical bandwidth limit for blobspace is ~768 kb/block, or 64 kb/sec.
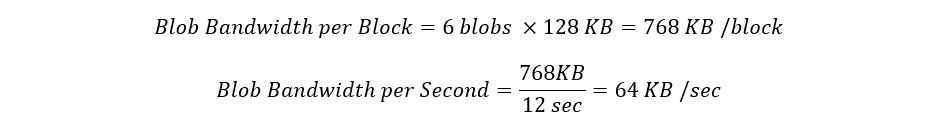
This leads us to the inevitable doom cycle: temporary blob saturation → dominant L2 moving to an alt-DA layer to support network → drop-off in blob saturation → ETH becomes inflationary again. Take Base for example again, it currently holds the largest percentage of blob submitters at ~34%. If any chain is eventually incentivized to opt to an alt-DA in this scenario, it’s usually the one making the most compromise of being beholden to the throughput limitations of the L1.

Does this suggest that value accrual through the DA layer is a fruitless endeavor?
2.5 Alt-DA – A Race to Zero
The successful scaling of throughput for Ethereum has come at the expense of trading off the actual revenue generating parts of the stack (execution/ sequencing/ MEV). Sure, settlement was a primary source of value accrual for Ethereum pre-EIP 4844; however, DA as a commodity is trending to zero as we move more towards the hyper-performant capacities of newer-gen blockchains. Celestia is a good example of this – their estimated annualized blob free revenue is ~$1.87mm while their fully diluted market cap sits at ~ $4.8B. $TIA currently trading at a 2,566x valuation to earnings indicates the poor value proposition of DA layers as a profitable business model.

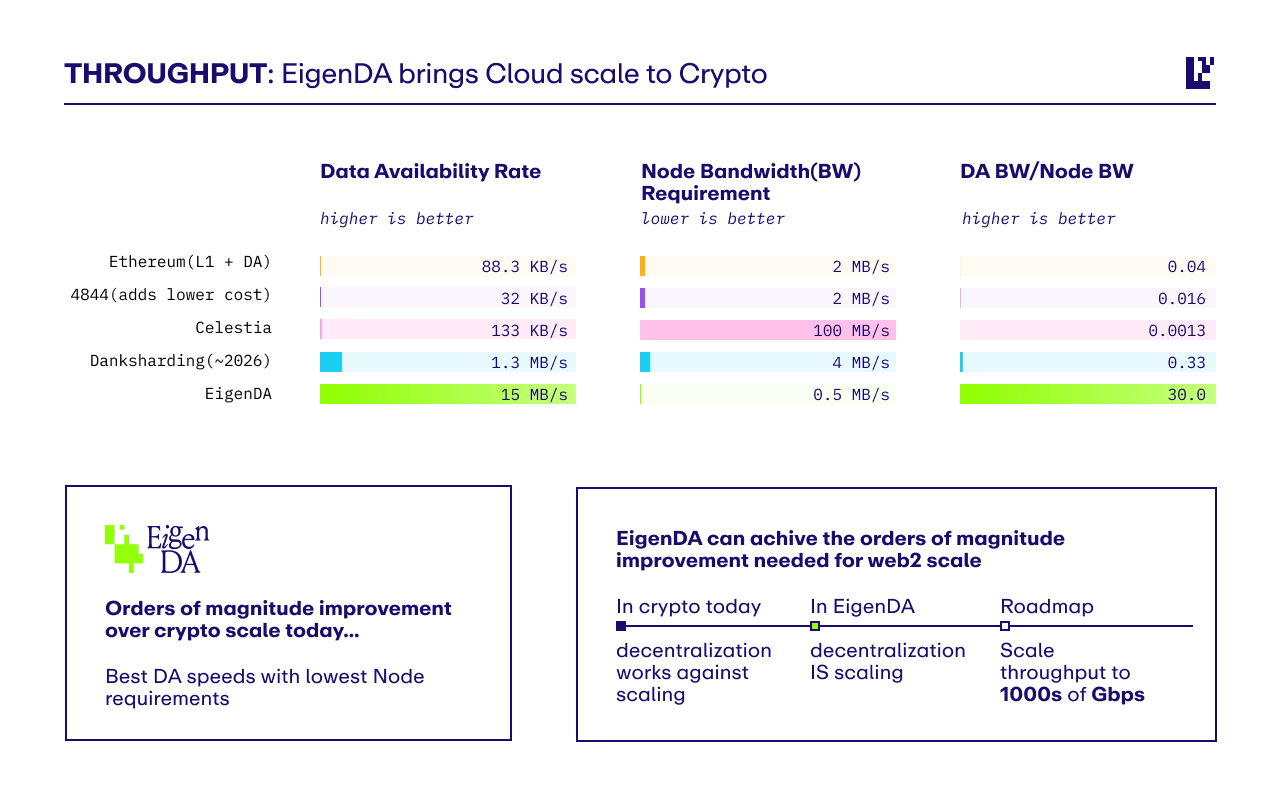
Among all of the current DA options, blobs are the least-efficient from a cost and performance basis. Assuming the size of blobspace is doubled during the Pectra upgrade, it will still be orders of magnitude less-efficient than existing DA solutions. Even in the scenario that Ethereum blobspace is saturated, alt-DA solutions already have a lead on the market in commoditizing this layer of the stack. EigenDA has recently announced that its mainnet is currently able to process 15+ MB/ sec; while Celestia has already rolled out a detailed roadmap to reach 1GB blocks.
3. Is Ethereum Losing its Value Prop?
All things considered; the question remains regarding the value proposition of Ethereum. I think holding out in hopes that L2s will somehow accrue value directly back to ETH via an increase in fees is wishful thinking in the short-term at least. As mentioned, I believe regardless of blob saturation, DA as a commodity is quickly trending towards zero. This is likely consequential of simply Moore’s Law, as exponential improvements in computing power lead to reductions in costs. We can see this with the significant gap of bandwidth between EigenDA compared to the rest of DA solutions.
Whether ETH becoming inflationary is bad for its economic value is really up for debate. The problem is that the “ultrasound money” narrative hinges on this idea that ETH needs to be net deflationary.
The opposing idea is that ETH is “programmable money” and that its value accrual is derived from the demand to use it as money (specifically as a gas token). However, this is yet another flawed narrative due to the aforementioned reasons above. What is stopping L2s from using their own native token as gas, or even opting to use a more stable alternative like a stablecoin? I’d even argue that L2s should use their own tokens for gas because there is simply no other value prop for these worthless governance tokens other than speculating on the give L2 as a beta to ETH performance.
The other consideration to make that debunks this narrative is that as fees trend cheaper, the need to hold excessive amounts of the gas token also diminish – just take Solana as a simple example - anyone shitcoining on Solana probably holds an average of .05 SOL to cover txn fees. A downtrend in overall fees is a consequent result of successful scaling.

3.1 Are L2s “Parasitic” to Ethereum?
The ongoing ETH economic accrual debate has sparked the question of L2s being “parasitic” to the L1. Even if we assume this is the case, it’s worth considering if this is inherently due to the design of the L1 that consequently propagates a parasitic relationship between the L2 and L1. Before blobs, there was arguably a greater symbiotic relationship between the L2 and the L1 – L2s benefit from ETH security and network effects, while ETH benefits from fees the L2s are paying to post calldata. Post-Dencun, L2s continue to reap the benefits from this relationship while paying significantly less to the L1.
Even if rollups are not intentionally parasitic to the L1, from a business perspective it makes sense to reduce overhead as much as possible. As mentioned earlier in the report, L2s have been sustaining average blob counts per block under the target level to keep fees near zero.

The extreme scenario is when L2s dilute value accrual from mainnet to the point where it jeopardizes the economic security of Ethereum. This eventually leads to less incentivized validators as the value of ETH drops (consequent of less ETH being burned/ inflationary metrics). The problem with this is that it creates a recursive cycle where value flows out of mainnet, disincentivizing validators to continue securing the chain which inevitably leads to more value leakage from users and assets leaving the L1.
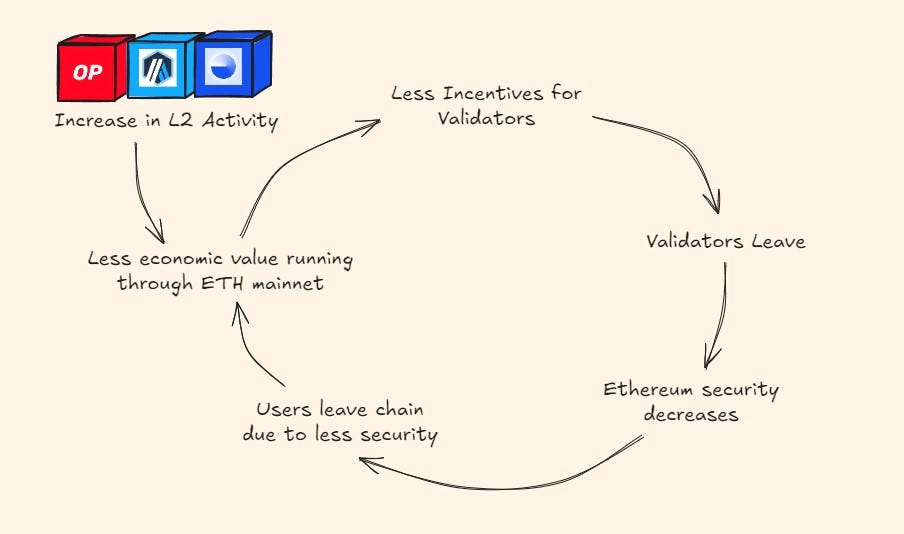
Granted, this is likely far from happening, but it’s worth pointing out where the current outflows/ inflows of capital are going.

Maybe the Ethereum community should abandon the “ultrasound money” narrative and focus on L2s bringing rapid market distribution to ETH at the cost of turning DA into a profit. If we hinge the value of ETH purely on the burn rate, then we’re forced to also derive the value from that single source. This is especially difficult considering that L2s have their own centralized sequencer that is responsible for capturing a majority of the fee revenue before settling back to ETH.
4. Optimizing for the L1 – The Role of the Sequencer
The costliest trade-off that Ethereum has made via the rollup-centric roadmap was forfeiting the sequencing part to the L2s. Here’s why:
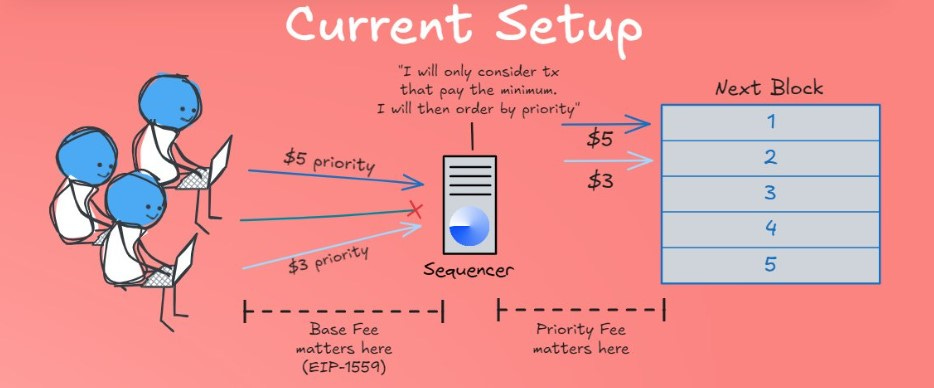
Currently, rollups execute all of the txns on their chain and sequence them via their own sequencer (in many cases these are single centralized sequencers) then post the calldata back to Ethereum in batches. There is a huge amount of arbitrage that is captured by the L2 sequencer and the difference of that capture is kept after paying DA fees to settle on the L1.
The arbitrage for L2s here is being able to capture priority fees which make up a disproportionate majority of value of overall fees. Transactions with the highest priority can end up paying significantly more—sometimes orders of magnitude higher. The problem is that since DA fees are batched, there is no discrepancy between the amount that is paid back to the L1 between high-value priority fees and low-value spam – the L1 essentially doesn’t benefit from an increase in priority fees on the L2, and this is exactly where the majority of fee revenue comes from.

The reason why L2s are able to make this price discrimination in fees is due to sequencer priority. With sequencer priority, users can influence the position of their transaction in the queue by paying a higher fee, specifically a priority fee – this ensures quicker inclusion in a block. Transactions with less urgency are still processed but at a lower fee, contributing to higher TPS. This is how the L2s and high-throughput L1s are able to balance between maintaining high TPS and generating substantial revenue.
The marginal, low-value txns are processed at lower fees, supporting high throughput. Meanwhile, the bulk of network revenue comes from users willing to pay premium fees for priority. Since the DA layer cannot differentiate between high-value and low-value txns, it isn’t able to capture sufficient revenue.
It then becomes apparent that in order to accrue this value back to mainnet, enshrining the sequencing portion of the stack is essential. This is where we explore based rollups as an option. 👇
4.1 Based Rollups – Accruing Value back to the L1
In a based rollup, the L1 validators are responsible for sequencing L2 transactions. This means that the rollup no longer has an independent sequencer; instead, it leverages the existing L1 infrastructure. Validators who are already proposing and confirming blocks on Ethereum are also tasked with ordering and processing transactions from the rollup. This integration results in the rollup inheriting the security and decentralization properties of the Ethereum base layer. It also means that the rollup is less vulnerable to issues like sequencer downtime or centralization risks.
Since L1 validators are now involved in the rollup’s transaction sequencing, the economic incentives between the L1 and L2 become more closely aligned. Validators benefit directly from the activity on the rollup, which can increase their staking rewards through transaction fees and potentially through MEV auctions. Consequently, this could lead to an increased demand for L1 block space redirecting the current value accrual back to Ethereum.
Within the based rollup architecture, only the execution is handled by the L2. There’s no need for additional consensus mechanisms or fallback solutions. The L1’s existing consensus model ensures the integrity of transaction sequencing for the rollup.
Transaction Order Flow:
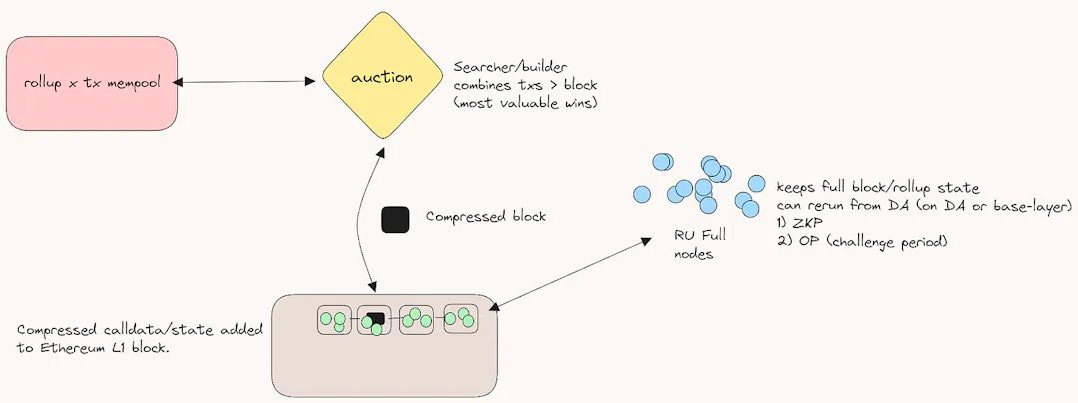
We’ll use Taiko as an example, as it is the most current iteration of what this looks like in practice:
Transactions on the L2 are submitted into their own mempool where they are then bundled by the searchers into L2 txn bundles. The searchers will continuously scan the mempool for high-value arbitrage or MEV opportunities before bundling these txns. These txn bundles are then submitted to the L2 block builders.
The block builder’s role is to construct an optimal block by ordering these transactions in a way that maximizes rewards, often focusing on MEV. In the case of Taiko, these block builders include the L2 txns in the block they are constructing for the Ethereum L1. The block is then compressed into a smaller, more efficient form that retains all necessary txn data.
The L1 proposer, a validator selected by Ethereum's PoS mechanism, receives the block from the block builder which includes both L1 and L2 txns. The proposer then finalizes and submits this block to the L1, where it undergoes validation by other network validators. The compressed L2 txns, now included in the L1 block, are posted to Ethereum. This ensures that the transaction data is available for future reference or dispute resolution.
4.2 Synchronous Atomic Composability – Incentivizing the L2
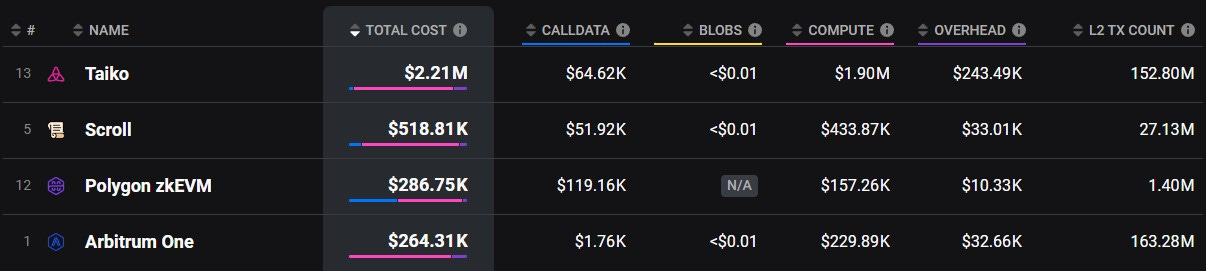
This sounds all great, but what are the incentives for existing rollups to become based rollups? If we take a look at the onchain total costs for L2s over the last 90 days we can see that Taiko, a based rollup, has incurred the highest costs to operate at $2.21M, nearly 10-fold of total costs of Arbitrum.
Synchronous atomic composability
Probably one of the main benefits of becoming a based rollup outside of inheriting the liveness guarantees of Ethereum is the idea of synchronous atomic composability. In the context of based rollups, synchronous composability ensures that operations on the L2 can immediately and directly interact with L1 within the same transaction context, without delays or the need for intermediate steps that span multiple blocks. This synchronous interaction is crucial for scenarios where the outcome of an L2 operation depends on the immediate state or action on the L1, and vice versa.
The transaction executes steps on both L2 and L1 in a tightly coupled manner, within the same logical transaction context. For instance, a DeFi protocol might execute a transaction on L2 that immediately interacts with L1 to confirm a state change (such as a cross-layer token transfer) and then continues executing further steps back on L2.
If any part of the transaction across either L2 or L1 fails, the entire transaction is rolled back across both layers. This rollback ensures that users are protected from incomplete operations or state inconsistencies that could arise from partial execution.
4.2.1 Taiko
Suppose a user wants to perform a cross-layer arbitrage that involves:
Borrowing funds on Taiko (L2)
Swapping those funds for another asset on Ethereum (L1)
Moving the swapped assets back to Taiko (L2) for another financial operation
The transaction components on Taiko and Ethereum interact in real-time, with immediate state updates as the transaction moves between layers. The entire sequence of operations, spanning both L2 and L1, is treated as a single atomic transaction. If the swap on Ethereum fails due to slippage or network congestion, the borrowing on Taiko is reverted, and the user’s assets and state are restored to their original condition, preventing any loss or inconsistencies.
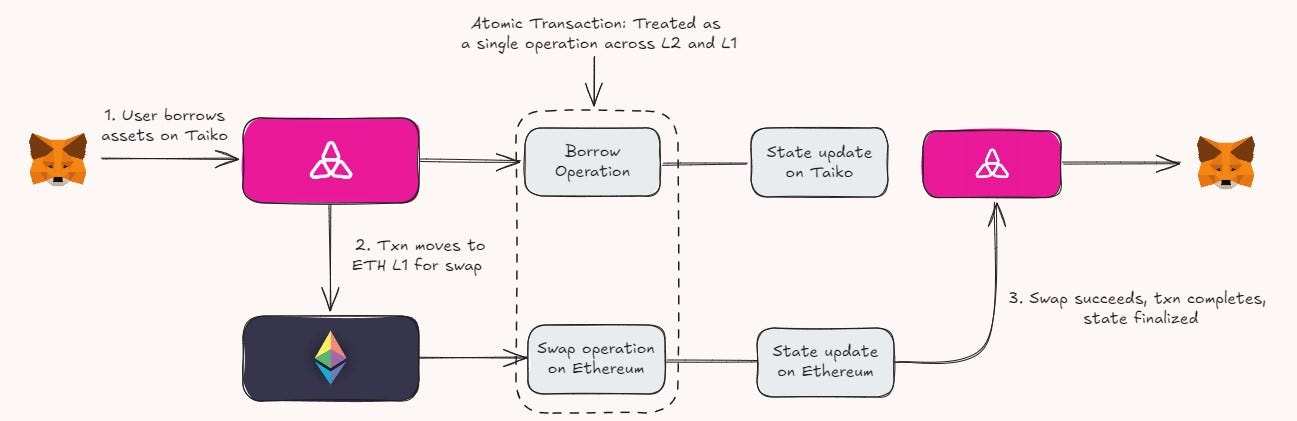
However, this doesn’t come without its challenges, the main one being latency and timing issues. Ethereum L1 currently operates within ~12sec block times. In contrast, L2s may have different, often faster, processing times due to their off-chain nature. Coordinating transactions that require real-time interaction between L1 and L2 can introduce latency issues – the challenge with this is ensuring operations execute within the same logical txn without any asynchronous delays.
Latency becomes a factor as well, as the communication between the L2 and L1 are required to propagate txn data across the network. If the timing between the layers isn’t tightly synchronized it will affect real-time execution.
4.3 Based Preconfirmations
The solution to this latency and timing issue lies within based pre-confirmations.
Preconfirmations provide early signals of transaction acceptance or rejection before full block finalization, effectively reducing the perceived confirmation time. Based pre-confirmations are an extension of the preconfirmation concept tailored specifically for based rollups, where rollups rely on Ethereum validators for sequencing and finalization of transactions. These pre-confirmations allow L2 operations to proceed with the assumption that the L1 part of the transaction will be confirmed as expected. This significantly reduces the overall latency and improves the responsiveness of cross-layer operations.
Chainbound’s Bolt is focused on enabling sub-second pre-confirmations on Ethereum.

Of course, based pre-confirmations are not without their own inherent challenges as well. Assumed finality/ trust assumptions and MEV capture are a couple notable issues.
Based preconfirmations rely on the assumption that the L1 validators will eventually confirm the transaction. While the preconfirmation offers a high probability of success, it is not a guarantee of finality until the block is fully finalized on L1. This introduces a trade-off between speed and security. If an application assumes that a preconfirmation is equivalent to final confirmation, it risks acting on transactions that might later fail.
Example: An L2 protocol might prematurely release funds based on an L1 preconfirmation, assuming that the transaction will be finalized. If, for any reason, the L1 finalization doesn't occur (e.g., due to a validator failure or network partition), the L2 could end up in an inconsistent state.
On the topic of MEV: Since based preconfirmations rely on L1 validators to provide early confirmation of L2 txns before full block finalization, validators might have conflicting incentives due to MEV opportunities. For example, an L1 validator could delay the inclusion of certain L2 txns or prioritize other txns that offer higher MEV, even if the preconfirmation has been signaled. If L1 validators exploit MEV, it could result in L2 transactions being delayed or even preconfirmed but never finalized on L1. This would create a scenario of exacerbating MEV opportunities.
For now, let’s stick to our topic on scaling, and save MEV and preconfirmations for later before we get lost in the based rollup rabbit hole.

5. Hyperscale EVMs & Rollups
This wouldn’t be a proper report on scaling if we didn’t cover high-throughput L1s and notably a couple of L2s focused on hyper optimizing on the scaling front. We’ve focused on the concept of based rollups, synchronous atomic composability, and the idea of enshrining the sequencer role to the Ethereum L1. These are all potential solutions to solving the ETH value accrual problem, however, at the expense of compromising on throughput to some degree.
Enshrining the sequencer in the L1 requires all transaction sequencing for rollups to depend on L1 validators. This inherently creates a latency bottleneck relative to Ethereum’s ~12sec block finality time. The synchronization overhead also increases with the tight integration of the L1 and L2. Cross-layer transactions require state proofs, consistent data availability, and atomic execution guarantees, all of which add computational complexity.
On the opposite spectrum, L2s like MegaETH and Rise Chain are juicing the sequencer to its capacity and implementing parallel execution to maximize for throughput (both claiming to achieve 100k TPS). In this section of the report, we’ll focus on the current bottlenecks of the EVM and the solutions aiming to hyperscale on throughput, alternative to the approach of based rollups.
Some key components to touch on:
State Access (Latency)
Centralized Sequencers
Parallel Execution
5.1 State Access Latency
In rollups, particularly optimistic and zk, the current state must frequently be validated or updated by the L1, especially for settlement, finality, and dispute resolution. When the L2 needs to access or confirm state from the L1, it results in delays, since L1 transactions must be processed and finalized (which can take several blocks). This back-and-forth introduces significant latency. For rollups, proving the correctness of transactions (through either fraud proofs in optimistic rollups or validity proofs in zk-rollups) requires submitting data to the L1. Until this data is verified and finalized on the L1, the state on L2 may not be considered final, leading to delayed access to certain state changes.
5.1.1 Rise Chain
Rise Chain addresses the issue of state access latency through Versioned Merkle Tree system to minimize disc compaction. Traditional rollups face latency due to the time it takes to fetch and update state data, especially when multiple transactions modify blockchain states sequentially. Rise Chain's VMT allows for more efficient state access by tracking the state across different versions without requiring the full re-computation of the Merkle root for each block. This means nodes can quickly retrieve historical or current states without having to re-process the entire state tree.
The storage and retrieval of state data is also optimized by RiseDB, a custom-built, delta-encoded log-structured database. Delta encoding records only the changes (deltas) between consecutive states rather than storing full copies of each state. This drastically reduces the amount of data that needs to be written to disk and retrieved during state updates. Log-structured databases write all changes to a log file sequentially, avoiding random writes and improving performance on traditional storage systems like SSDs.
5.2 MegaETH – Hyperscaling Ethereum
MegaETH takes an alternative approach to addressing state access latency by its use of in-memory storage to hold the entire blockchain state. By leveraging a large amount of RAM instead of slower storage mediums like SSDs, MegaETH eliminates the typical read/write latencies associated with state access. With the blockchain state stored entirely in RAM, MegaETH can provide nearly instant access to state data during transaction execution.
Now, the topic of debate with hyperscaling an L2 on Ethereum begs the question of: what’s stopping the L2 from simply becoming an L1? From MegaETH’s perspective, this is inherently not viable because they are basically a centralized sequencer and there needs to be a level of decentralization which in this case is tied to the base layer (Ethereum). MegaETH optimizes purely for performance while leaving the decentralization and security components of the scalability trilemma for Ethereum to handle – essentially creating a scenario where you have relatively centralized block production with a very decentralized and trustless block validating network. This was something that Vitalik emphasized in his endgame post.

MegaETH achieves hyperscale through what’s called node specialization. It employs specialized nodes to divide different roles and responsibilities across the network in order to optimize for performance.
Node Specialization
Sequencer: a single centralized node that is responsible for ordering and executing all transactions on the L2. By centralizing the sequencer, MegaETH reduces complexity and ensures rapid transaction inclusion. However, this comes with trade-offs related to trust and potential censorship risks. MegaETH mitigates this by enabling a fallback mechanism and what’s known as “rotational sequencers”.
Rotational sequencers refer to the rotation of responsibility for ordering and executing transactions between a few geographically distributed nodes. Should one sequencer node fail, the network can continue to function efficiently by rotating the role to another sequencer. This is a high-end server (e.g., 100 cores, 1TB RAM, and 10 Gbps network).
Provers: nodes specialized to handle the validation and proof generation necessary for ensuring txn correctness without requiring full txn details. These are specialized hardware (e.g., GPU, ASIC, etc.)
Full Nodes: nodes that maintain a copy of the entire blockchain state, ensuring data availability and allowing independent verification of transactions. These are lower-end hardware requirements (e.g., 8 cores, 8 GB RAM, 100 Mbps network).
The sequencer orders and executes all transactions on the L2. It batches these transactions and submits them to L1 for finalization. After sequencing, prover nodes generate optimistic proofs to verify the correctness of the batched transactions and ensure that the state transitions are valid. Full nodes validate the proofs, maintain the entire blockchain state, and ensure data availability for future reference.

The whole point of node specialization is that it provides nodes with different hardware configurations to specialize in handling different tasks in the execution pipeline. In the case of MegaETH, a single high-end server acts as the centralized sequencer allowing it to maximize on throughput.
5.3 Centralized Sequencers
The discussion around centralized sequencers has been a contentious debate in the corners of CT where the ethos of Ethereum has always lied in its decentralization and censorship-resistance. If we’re just juicing up a single sequencer to maximize for throughput, doesn’t that defeat the whole point of a decentralized blockchain? The answer is quite nuanced, and even Vitalik had this to say about it:
There are two main technical implementations to make the case for centralized sequencers to be viable on the L2: Forced inclusion & a fallback mechanism (in case of sequencer failure).
Forced Inclusion: Forced inclusion is a mechanism to ensure that a centralized sequencer cannot indefinitely censor or ignore valid transactions submitted by users. It guarantees that any valid transaction submitted to the rollup must eventually be included in the next available batch processed by the sequencer. The forced inclusion rule could be enforced by an external system, either through governance or smart contracts, that monitor the sequencer’s behavior. If the sequencer attempts to censor transactions, Ethereum validators would act as the final arbiter in that situation.
Fallback Mechanism: In the case of sequencer failure or malicious behavior, a fallback mechanism would ensure that the network continues to function even if the primary sequencer fails. This would involve backup or alternative sequencers stepping in when the primary sequencer behaves maliciously or becomes unavailable. If the centralized sequencer censors or delays transactions beyond an predefined threshold limit, the fallback system triggers, allowing another sequencer to process the pending transactions. In the case of MegaETH, this could be represented as the rotational sequencers.
There is a specific inefficiency with forced inclusions that is inherent in the nature of its design that requires all txns to be indiscriminately included in the sequenced batch (assuming the txn is valid). This comes in the form of exploitation of spam attacks. If we introduce the possibility of a large volume of low-value spam transactions, this could lead to increased latency, reduced txn prioritization, and overall, second order effects of network congestion. This was the case with Solana earlier this year (memecoin activity, ore mining, spam bots) when txns were not finalizing and being subsequently dropped. A low fee environment inherently incentivizes low-value spam.

5.3.1 Decentralizing Rollups
MegaETH’s position on the decentralization spectrum highlights the already prominent discussions around existing L2s and their path towards becoming sufficiently decentralized. According to L2beat, only two rollups are currently considered to be a stage 2 rollup.

A Stage 2 rollup is considered to have achieved full decentralization and independence, moving beyond reliance on centralized components or permissions that typically characterize earlier stages. The progression to Stage 2 involves removing the “training wheels,” which means eliminating dependencies such as centralized sequencers, permissioned fraud proof systems, or restricted node access. In this stage, the rollup becomes fully self-sufficient and permissionless, with decentralized control over transaction processing, fraud proofs, and upgrades.
*Note that the following diagram is a rough outline of what l2beat considers for each stage. The level of “decentralization” could vary between rollups simply meeting those requirements. However, it highlights how far off the majority of rollups are from achieving this.
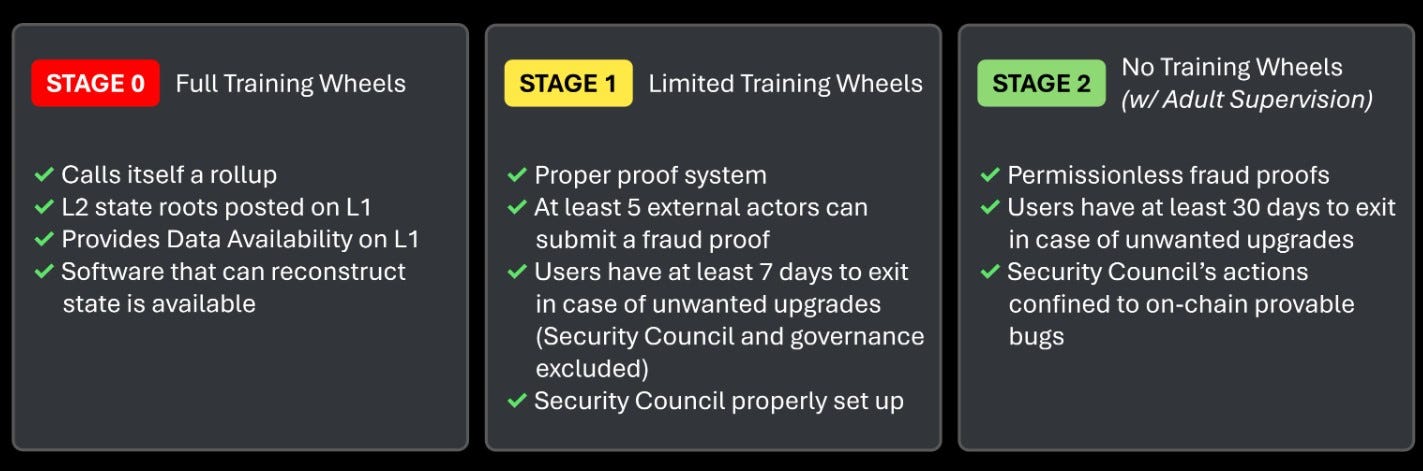
What’s more concerning is that only 4 other rollups are considered to be stage 1, with Arbitrum and Optimism being two out of the four. All other L2s are stage 0.
5.4 Parallel Execution
Parallel execution is one of the key components in the hyperscalers today (Solana, Aptos, Sui, etc.) and notably Monad (which we will cover). The basic premise is the ability to process multiple transactions or smart contract operations simultaneously, rather than sequentially.
Why Parallel Execution Matters
To use a simple example, in traditional blockchains like Bitcoin and Ethereum, txns are processed sequentially by every node in the network. Each node executes txns one after another to update the blockchain's state. While this ensures consistency and determinism across the network, it creates a performance bottleneck. Parallel execution offers a solution by allowing multiple txns to be processed at the same time.
So why doesn’t Ethereum just implement parallel execution?
There are a number of reasons why Ethereum cannot simply adopt parallel execution immediately:
Shared global state and state dependencies
EVM design limitations
Determinism and consensus requirements
Technical complexity and implementation challenges
Prioritization of alternative scaling solutions (rollups)
The EVM was originally designed for sequential execution of transactions to ensure determinism and consistency across all network nodes. Parallel execution can lead to different nodes arriving at different states if not perfectly synchronized. This means that variations in transaction execution order or conflict resolution can introduce non-determinism and undermining the consensus protocol.
Modifying Ethereum's core protocol to support parallel execution would involve significant alterations to the transaction processing model, state management, and potentially the consensus algorithm. This may be why pursuing the rollup-centric roadmap was the likely option. However, there is an L1 that is improving on the existing design of the EVM, and parallel execution is at the forefront of its architecture.
5.5 Monad – Improving the EVM Design
Monad is a high-throughput EVM compatible L1 focused on addressing the inherent inefficiencies in traditional EVM chains by redesigning both consensus and execution layers. It’s essentially what Ethereum would have been if it were to launch today – an improvement in scaling on the L1 layer while maintaining security and decentralization.
Monad optimizes in four major components:
Parallel Execution:
Parallel execution in Monad is designed to significantly boost txn throughput by processing multiple txns simultaneously across different threads, rather than executing them sequentially. This is achieved through optimistic parallel execution, where the system assumes that most transactions do not have conflicts (e.g., two txns trying to modify the same account or state variable).
Monad’s parallel execution relies on what’s referred to as Optimistic Concurrency Control (OCC), which detects and resolves conflicts during execution. If two txns attempt to modify the same state, Monad identifies the conflict and reschedules one of the txns for re-execution. This ensures that the final state remains correct without compromising parallel performance.
Monad believes that the single biggest bottleneck for execution is not CPU time, but in fact state access. To quote Keone ~
“Parallel execution does not increase TPS much if your database can’t handle it”.
For this reason, a custom database to support parallel execution was designed.
MonadDB:
MonadDB is the custom database designed to support Monad’s parallel execution model. It handles state storage and transaction data, allowing multiple txns to read and write to the database simultaneously. Unlike Ethereum’s Merkle Patricia Trie structure, MonadDB uses a Patricia Trie with asynchronous I/O, facilitating fast state updates and ensuring compatibility with parallel transaction execution.
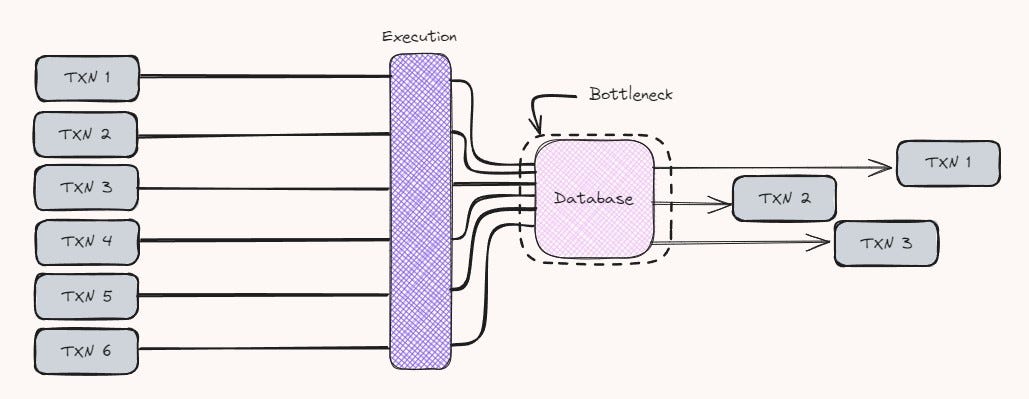
Deferred Execution:
Deferred execution decouples consensus from transaction execution, enhancing efficiency. In traditional blockchains like Ethereum, consensus and execution occur within the same block window. Monad separates these processes, allowing transactions to be executed after consensus is reached. Once a block achieves consensus, execution begins while the next block’s consensus process is underway. This asynchronous execution model ensures that there is no idle time between consensus and execution, maximizing resource utilization and minimizing latency between block finalizations.
MonadBFT:
MonadBFT is Monad’s proprietary consensus mechanism, an enhanced version of HotStuff. It achieves finality through a two-chain commit rule, where blocks are finalized only after observing two consecutive quorum certificates. This approach improves performance by minimizing communication phases and optimizing block proposal and validation.
5.5.1 Superscalar Pipelining
Monad uses superscalar pipelining, similar to techniques used in modern CPU design, to divide transaction processing into stages (like signature verification and state access) that run concurrently. This approach allows Monad to maximize resource utilization by overlapping execution tasks, compared to the linear execution model of Ethereum.

Monad divides transaction execution into distinct phases like signature verification, state access, and transaction execution. These phases can run concurrently across multiple threads, similar to how a CPU handles multiple instructions at once. For instance, while one stage of a transaction (e.g., verifying signatures) is in progress, the next transaction can begin processing its state access, overlapping the two tasks. By keeping multiple transaction stages active simultaneously, it ensures that tasks are not waiting for sequential completion.
6. Valuing Crypto Networks – Key Takeaways
If Monad is essentially a “better” version of the EVM, and improves on all the scalability limitations of the ETH L1 while retaining sufficient security and decentralization, wouldn’t that make Ethereum’s value prop obsolete?
It’s no surprise that Ethereum is currently facing an identity crisis as the “ultrasound money” narrative falls to the wayside. The problem is that as technology advances, costs of operations and resources decline exponentially. Hyperscaling inevitably means a race to zero, and we are witnessing this with the lack of fee revenue back to ETH mainnet.
Arguably, what’s more concerning for Ethereum is that as it tries to play “catch up” and compete with the hyperscalers (Solana, newer-gen alt-L1s), it diminishes its core value prop of being censorship resistant and the most decentralized. Unfortunately, Ethereum is between a rock and a hard place. A lot of the scaling, even from L2s is inherently constrained by the performance and throughput of the L1. Because rollups require the L1 to verify the correctness of the state, their scalability inherently becomes limited to the L1’s capacity to publish transaction data. As a result, this places a higher computational burden on L1 validators. When this bandwidth requirement grows it makes solo staking increasingly difficult (especially for those Raspberry Pi’s).
It's worth considering how we came to this sentiment around ETH. Typically in crypto, price go up = gud tech/ price go down or sideways = bad tech. It could very well be the dynamics around the market itself, but there is no denying that users tend to gravitate towards smoother UX, sub-second txns, and negligible fees, all which Solana has proven to provide. I say this as an on-chain user of ETH; it’s agonizing trying to execute simple swaps, bridges, and transfers. This doesn’t necessarily imply that Solana is undervalued, however. If that was the case, why do all these dead L2s with little to no volume demand such high valuations?

Crypto is a market that is highly narrative driven. This is why I believe VCs will continue to dump endless capital to the next rollup or alt-L1s. Maybe it’s worth acknowledging that these infra protocols are indeed worthless and going to zero at some point (not financial advice). Until we get a shift of capital towards actual use case products, I’m sure we’ll keep playing musical chairs on the next L1 or L2 debating the semantics of “ultrasound” money and value accrual on CT.
*Nothing in this report should be taken as financial or investment advice.
References:
https://dune.com/hildobby/ethereum
https://dune.com/hildobby/blobs
https://dune.com/oplabspbc/superchain-l2-economics
https://www.coinbase.com/institutional/research-insights/research/market-intelligence/eth-and-the-rise-of-l2s
https://modular.4pillars.io/BasedRollups
https://docs.riselabs.xyz/rise-stack/pevm.html
https://megaeth.systems/research
https://docs.monad.xyz/